Network Speed: 9 Essential Strategies for Effortless AI Latency
Discover 9 essential strategies to optimize network speed and reduce AI latency for edge computing applications with practical implementation tips.

Introduction
Key Takeaways
- Latency management is critical for real-time AI applications that depend on instant data processing at the edge
- Strategic infrastructure placement, routing optimization, and hardware upgrades can dramatically reduce processing delays
- Continuous monitoring and proactive troubleshooting ensure sustained network speed performance for AI workloads
- Practical implementation strategies exist that balance cost, complexity, and performance gains
- Understanding the relationship between fiber network architecture and AI efficiency unlocks competitive advantages
As one of the co-founders of FiberInsider.com, I've witnessed firsthand how latency in fiber networks can make or break AI-driven applications. A few years back, we optimized a client's network for their new AI application that required real-time data processing—any delay could severely impact decision-making capabilities. That project crystallized an essential truth: network speed directly influences the effectiveness of AI operations.
The challenge was clear from day one. The client's edge AI application needed to process sensor data, make split-second decisions, and execute actions without perceptible lag. Traditional network architectures simply couldn't deliver the performance required. We had to rethink everything from routing paths to data center placement, deploying edge infrastructure closer to data collection points to minimize the distance information had to travel.
What emerged from that experience was a comprehensive understanding of the strategies that actually move the needle on AI latency. It's not just about faster fiber or bigger pipes—though those help. It's about intelligent design, strategic optimization, and continuous refinement across multiple layers of your network stack.
Today's AI applications at the edge demand more than ever before. Autonomous systems, real-time analytics, and intelligent automation all depend on networks that can deliver data with minimal delay. The gap between adequate network speed and optimized performance often determines whether an AI deployment succeeds or struggles.
In this guide, we'll walk through nine essential strategies that address AI latency from every angle. You'll discover how infrastructure decisions, routing techniques, hardware choices, and monitoring practices work together to create networks that support demanding edge AI workloads. These aren't theoretical concepts—they're battle-tested approaches that deliver measurable improvements in real-world deployments.
Whether you're planning a new edge AI deployment or optimizing an existing network, understanding these strategies will help you build infrastructure that keeps pace with your AI applications' demands.
Sources
Explore 9 essential strategies to reduce AI latency and improve network speed for edge AI applications efficiently.
Focus keyword: network speedTone: professional
Table of Contents
- Introduction — Hook readers with Brian's real-world experience optimizing a client's network for AI applications, establishing the critical importance of latency management in fiber networks for edge AI, and previewing the practical strategies covered in the article.
- Table of Contents — Provide navigational structure for the article's key sections.
- What Is Latency in Fiber Networks and Why It Matters for Edge AI — Define latency in technical but accessible terms, explain the physics of data transmission through fiber, differentiate between propagation delay and processing delay, and establish why milliseconds matter for AI decision-making at the edge.
- Key Metrics for Measuring AI Latency in Network Performance — Introduce essential latency metrics (round-trip time, jitter, packet loss), explain how to benchmark network speed for AI workloads, and provide context for acceptable latency thresholds in different edge AI scenarios.
- Infrastructure Optimization: Edge Data Centers and Network Architecture — Explain how strategic placement of edge data centers reduces physical distance, discuss network topology considerations, cover the role of colocation facilities, and demonstrate how infrastructure decisions directly impact AI latency.
- Smart Routing and Path Optimization Techniques — Detail methods for optimizing routing paths, explain BGP optimization, discuss traffic engineering strategies, and show how intelligent routing reduces unnecessary hops and minimizes AI latency in fiber networks.
- Hardware and Equipment Upgrades That Reduce Processing Delays — Discuss the impact of network hardware on latency, cover switches and routers with low-latency capabilities, explain buffering and queuing issues, and provide guidance on equipment selection for AI-optimized networks.
- Protocol Selection and Software-Level Optimizations — Examine how protocol choices affect latency, discuss TCP versus UDP for AI applications, cover compression and serialization strategies, and explain software-defined networking benefits for latency reduction.
- Continuous Monitoring and Proactive Troubleshooting Methods — Outline best practices for ongoing latency monitoring, introduce tools and techniques for identifying bottlenecks, explain how to diagnose common latency issues, and emphasize proactive maintenance for consistent network speed.
- Practical Implementation: Building a Low-Latency Network for Edge AI — Synthesize the strategies into an actionable implementation framework, discuss phased deployment approaches, address budget considerations, and provide a roadmap for organizations looking to optimize their fiber networks for AI workloads.
- Conclusion — Reinforce the critical relationship between latency management and AI performance, summarize the nine key strategies covered, and encourage readers to take action on optimizing their networks with a forward-looking perspective on edge AI evolution.
11 sections
What Is Latency in Fiber Networks and Why It Matters for Edge AI

Latency is the delay it takes for data to move from one point to another across a network. Think of it as the time between when you send a request and when you receive a response. In fiber networks, latency measures the time it takes for data to travel from your device to the server and back.
While bandwidth tells you how much data can flow through your network, latency tells you how quickly that data can make the trip. For edge AI applications that need to make split-second decisions, this timing is everything.
Understanding the Physics of Fiber Transmission
Data travels through fiber optic cables as pulses of light, moving at roughly two-thirds the speed of light in a vacuum. Even at these incredible speeds, distance matters. A signal traveling 1,000 miles through fiber takes about 8 milliseconds just for the physical journey.
This physical travel time is called propagation delay. It's determined by the distance the signal must cover and the refractive properties of the fiber itself. No amount of optimization can eliminate propagation delay—it's a fundamental constraint of physics.
But propagation delay is only part of the story. Your data also encounters processing delays at every network device it passes through—routers, switches, and servers all add small increments of time as they handle, inspect, and forward packets.
Why Milliseconds Matter for Edge AI
Edge AI applications process data close to where it's generated, enabling real-time decision-making. Autonomous vehicles, industrial automation systems, and smart security cameras all rely on ultra-low latency to function safely and effectively.
Low latency under 50 milliseconds is often considered ideal for demanding applications. For edge AI, the requirements can be even stricter. A self-driving car making emergency braking decisions can't afford delays of even 100 milliseconds—that's the difference between a safe stop and a collision.
High latency can make AI applications slow or unresponsive, undermining their core value proposition. When AI systems are deployed at the edge specifically to avoid the delays of sending data to distant cloud servers, network speed becomes the critical enabler of the entire architecture.
The Real-World Impact on AI Performance
In practical terms, latency affects three key aspects of edge AI performance. First, it determines response time—how quickly the AI can act on new information. Second, it impacts throughput—how many AI inference operations can be completed per second. Third, it influences reliability—high or variable latency can cause timeouts and failures.
For applications like video analytics, facial recognition, or predictive maintenance, these delays compound quickly. An AI system processing 30 frames per second needs consistent, predictable latency on every frame to maintain real-time performance.
The difference between 10 milliseconds and 100 milliseconds of latency might seem small on paper, but in edge AI deployments, it's often the difference between a system that works and one that doesn't.
Sources
Key Metrics for Measuring AI Latency in Network Performance
When you're optimizing network speed for AI applications, you need concrete metrics to measure success. The three fundamental indicators—round-trip time, jitter, and packet loss—tell you everything about how your network handles real-time AI workloads.
Round-Trip Time: The Foundation of Latency Measurement
Round-trip time (RTT) measures how long it takes for data to travel from source to destination and back again. For edge AI applications, RTT is your baseline metric. Lower RTT means faster AI decision-making, which is critical when you're processing sensor data or running real-time analytics at the edge.
Typical RTT benchmarks vary by use case. Autonomous vehicle systems might require RTT under 10 milliseconds, while industrial monitoring applications can often tolerate 50-100 milliseconds. The key is understanding your specific AI workload requirements and measuring against those thresholds.
Jitter and Its Impact on Consistent Performance
Jitter measures the variation in packet arrival times. Even if your average latency looks good, high jitter creates unpredictable performance that can disrupt AI inference cycles. When packets arrive at irregular intervals, your AI models may process incomplete or outdated data, leading to poor decision quality.
For edge AI deployments, keeping jitter below 5-10 milliseconds ensures consistent model performance. Applications requiring real-time responses—like video analytics or predictive maintenance—are particularly sensitive to jitter fluctuations.
Network Speed and Packet Loss
Packet loss occurs when data packets fail to reach their destination. Even small amounts of packet loss can significantly impact network speed and application performance. When packets are lost, they must be retransmitted, adding delay and consuming bandwidth that could otherwise support your AI workloads.
Quality of Service (QoS) policies help prioritize critical AI traffic, ensuring your most important applications receive the necessary bandwidth for optimal performance. By implementing traffic shaping techniques, you can limit data transfer during peak times and maintain speed for time-sensitive AI operations.
Benchmarking for AI Workloads
Benchmarking network speed for AI requires simulating realistic workloads. Start by identifying your AI application's data patterns—payload sizes, transmission frequency, and acceptable latency windows. Run continuous tests under various network conditions to establish baseline performance and identify potential bottlenecks.
Different edge AI scenarios demand different thresholds. Healthcare diagnostics might require sub-20ms latency with zero packet loss, while smart building systems could function effectively with 100ms latency and minimal packet loss tolerance. Understanding these nuances helps you set realistic performance targets and make informed infrastructure decisions.
Sources
Infrastructure Optimization: Edge Data Centers and Network Architecture
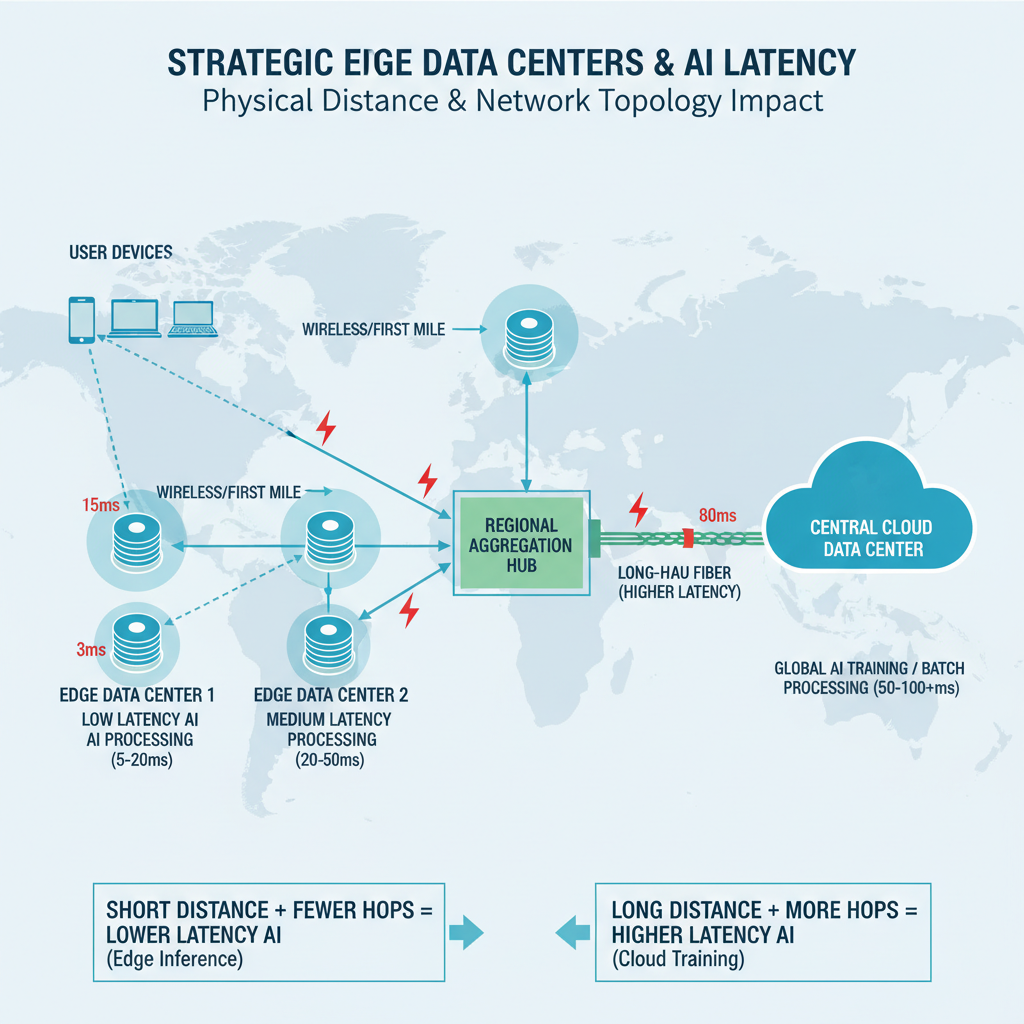
When it comes to reducing AI latency, your infrastructure decisions matter more than almost anything else. The physical placement of edge data centers, the design of your network topology, and even your choice of colocation facilities all play direct roles in determining how quickly data moves through your network. These aren't just technical details—they're foundational choices that can make or break your edge AI performance.
Strategic Placement of Edge Data Centers
The closer your edge data center sits to the point of data collection, the less distance your data needs to travel. This simple principle has enormous implications for AI latency. By deploying edge infrastructure near end users or IoT devices, you eliminate unnecessary round trips to distant cloud data centers. For AI applications requiring real-time processing—think autonomous systems or industrial automation—this proximity translates directly into faster response times and more reliable performance.
Consider the physical path your data takes. Every additional mile adds microseconds of delay. While that might sound negligible, those microseconds accumulate quickly in AI workloads that process thousands of requests per second. Strategic placement means analyzing where your data originates and positioning compute resources accordingly.
Network Topology Considerations for Low Latency
Your network topology—the way nodes and connections are arranged—fundamentally shapes latency outcomes. A well-designed topology minimizes the number of hops between source and destination, reducing both delay and the potential for congestion. Mesh topologies offer redundancy and multiple paths, while star configurations centralize traffic management. The right choice depends on your specific AI workload and geographic distribution.
Network segmentation also plays a critical role. By organizing devices and applications into smaller, manageable segments, you reduce congestion and improve overall performance. This approach ensures that high-priority AI traffic doesn't compete with less time-sensitive data flows, maintaining consistent low latency even under heavy load.
The Role of Colocation Facilities
Colocation facilities provide a practical middle ground between building your own data centers and relying entirely on distant cloud providers. By housing your equipment in strategically located colocation sites, you gain proximity to key network exchange points and fiber routes without the capital expense of constructing dedicated facilities. This positioning reduces latency by placing your infrastructure at the intersection of major network pathways.
These facilities also offer direct connections to multiple carriers and internet service providers, giving you flexibility in routing and redundancy. For edge AI applications, this means you can optimize paths dynamically and maintain performance even when individual links experience issues.
Infrastructure Decisions That Impact Latency
Optimizing network infrastructure requires attention to both hardware and layout. Regular updates to hardware and firmware ensure you're leveraging the latest performance improvements. Proper cabling, organized rack layouts, and thoughtful physical design all contribute to reducing signal degradation and processing delays.
Your infrastructure choices create the foundation for everything else. Even the most sophisticated routing algorithms or advanced protocols can't overcome fundamental limitations imposed by poor infrastructure design. By prioritizing strategic placement, thoughtful topology, and quality facilities, you set the stage for genuinely low-latency AI operations.
Sources
Smart Routing and Path Optimization Techniques
Optimizing routing paths is one of the most effective ways to reduce latency in fiber networks supporting edge AI applications. By minimizing the number of hops data packets take and selecting the most efficient routes, you can significantly improve network speed and reduce delays that impact AI performance.
Intelligent Routing Strategies
Intelligent routing involves analyzing network topology and traffic patterns to determine the most efficient paths for data transmission. Rather than relying on default routing protocols, advanced routing strategies consider factors like current network congestion, link quality, and physical distance to make real-time decisions about packet forwarding.
Implementing dynamic routing protocols allows your network to automatically adjust to changing conditions. When a particular path becomes congested or experiences degradation, the routing system can redirect traffic through alternative routes to maintain optimal performance.
Traffic Engineering for Network Speed
Traffic engineering strategies help you control how data flows through your network infrastructure. By implementing Quality of Service (QoS) policies, you can prioritize critical applications and ensure they receive the necessary bandwidth for optimal performance. This is particularly important for AI workloads that require consistent, low-latency connectivity.
QoS policies allow you to classify traffic based on application type, source, destination, or other criteria. Time-sensitive AI inference requests can be tagged with higher priority levels, ensuring they're processed ahead of less critical traffic during periods of network congestion.
Reducing Unnecessary Hops
Every router or switch a data packet passes through adds processing delay and increases the risk of congestion-related latency. Minimizing the number of hops between edge AI devices and processing resources is essential for maintaining low latency.
Strategic network design plays a crucial role here. By carefully planning your network topology and establishing direct connections between frequently communicating endpoints, you can eliminate unnecessary intermediate hops. This approach is particularly effective when combined with edge data center placement that positions compute resources closer to data sources.
Path Optimization Best Practices
Using wired connections with Ethernet cables instead of wireless alternatives can significantly improve network speed and reliability. Wired connections eliminate the variability and interference issues common with wireless transmission, providing more consistent latency characteristics.
Regularly reviewing and updating routing configurations ensures your network continues to operate efficiently as traffic patterns evolve. Automated path optimization tools can continuously monitor performance metrics and adjust routing decisions to maintain optimal network speed for your AI applications.
Sources
Hardware and Equipment Upgrades That Reduce Processing Delays
When it comes to optimizing network speed for AI applications, your hardware choices can make or break performance. The switches, routers, and network interface cards handling your data packets directly influence how quickly information flows through your infrastructure. Outdated equipment creates bottlenecks that compound latency issues, especially when AI workloads demand real-time processing.
Selecting Low-Latency Switches and Routers
Modern network switches designed for low-latency environments prioritize minimal processing delays and efficient packet forwarding. Look for devices with cut-through switching capabilities rather than store-and-forward architectures—they begin transmitting packets before the entire frame arrives, shaving microseconds off each hop. For AI-optimized networks, enterprise-grade equipment with dedicated ASICs (Application-Specific Integrated Circuits) typically outperforms general-purpose processors when handling high-throughput data streams.
Routers play an equally critical role in maintaining network speed. Equipment with hardware-accelerated routing tables and optimized forwarding engines reduces the time spent on routing decisions. When selecting routers for edge AI deployments, prioritize models that support advanced queuing mechanisms and offer granular control over traffic prioritization.
Understanding Buffering and Queuing Challenges
Buffering issues represent one of the most common yet overlooked sources of latency in network infrastructure. When packets arrive faster than a device can process them, they queue in memory buffers, introducing variable delays that disrupt time-sensitive AI operations. Deep buffer architectures, while protecting against packet loss, can inadvertently create "bufferbloat"—a condition where excessive queuing adds hundreds of milliseconds to round-trip times.
Shallow buffer configurations paired with intelligent queue management help maintain consistent low latency. Active Queue Management (AQM) algorithms dynamically adjust queue depths based on network conditions, preventing the buildup that degrades performance. For AI workloads requiring predictable response times, this approach proves far more effective than simply throwing more buffer memory at the problem.
Equipment Selection Guidelines for AI Networks
Optimizing network infrastructure requires updating hardware and firmware regularly, as well as ensuring proper layout and cabling to enhance performance. Start by establishing baseline performance metrics for your current equipment—measure packet processing rates, forwarding latency, and jitter under typical AI workload conditions.
When evaluating new hardware, consider the total processing pipeline from ingress to egress. Network interface cards with kernel bypass capabilities (like DPDK or SR-IOV) eliminate operating system overhead, delivering packets directly to applications. Similarly, switches supporting lossless Ethernet protocols prevent retransmissions that would otherwise introduce unpredictable delays.
Don't overlook the importance of proper physical infrastructure. High-quality fiber optic cables with appropriate connector types minimize signal degradation, while organized cable management prevents physical layer issues that manifest as intermittent latency spikes. The investment in structured cabling pays dividends when troubleshooting performance issues months or years down the line.
Firmware and Configuration Best Practices
Even the most advanced hardware underperforms without proper configuration. Measure and monitor network traffic to establish a baseline of normal performance, which helps in identifying when and how to optimize the network. Regular firmware updates address known performance issues and often include optimizations specifically targeting latency reduction.
Disable unnecessary features that consume processing cycles—protocols and services not required for your AI applications add overhead without benefit. Enable hardware offloading features for functions like checksum calculation and segmentation, freeing up CPU resources for packet forwarding. These seemingly minor adjustments accumulate into measurable improvements in overall network speed.
Sources
Protocol Selection and Software-Level Optimizations
When you're designing a network for edge AI applications, the protocols and software configurations you choose can make or break your latency targets. While hardware sets the foundation, your protocol decisions and software-level tweaks often determine whether you achieve millisecond-level responsiveness or struggle with delays that degrade AI performance.
TCP Versus UDP: Choosing the Right Protocol for AI Workloads
The battle between TCP and UDP isn't new, but it takes on fresh significance in AI contexts. TCP offers reliable, ordered delivery with built-in error correction—great for applications where data integrity trumps speed. However, that reliability comes at a cost: handshakes, acknowledgments, and retransmissions all add latency.
UDP, on the other hand, is a lightweight protocol that sends packets without waiting for confirmations. For real-time AI inference at the edge—think autonomous systems or live video analytics—UDP's lower overhead often makes it the better choice. You sacrifice guaranteed delivery for speed, which works well when occasional packet loss is acceptable and your application can handle missing data gracefully.
The key is matching protocol to use case. If your AI model processes sensor data where every millisecond counts and occasional gaps won't derail decisions, UDP shines. For training data synchronization or model updates where accuracy matters more than instantaneous delivery, TCP remains the safer bet.
Compression and Serialization Strategies
Reducing the size of data in transit directly improves network speed by lowering the volume of information that must travel across your infrastructure. Compression algorithms can shrink AI model parameters, inference requests, and results before transmission, cutting both bandwidth consumption and transfer time.
However, compression isn't free—it requires CPU cycles to compress and decompress data. The trick is finding the sweet spot where compression savings outweigh processing overhead. Lightweight algorithms with hardware acceleration support often deliver the best balance for latency-sensitive AI applications.
Serialization format matters too. Binary protocols like Protocol Buffers or MessagePack typically outperform text-based formats like JSON for AI data exchange, offering smaller payloads and faster parsing. When you're moving tensor data or model weights between edge devices and processing nodes, these efficiency gains compound quickly.
Software-Defined Networking for Dynamic Latency Optimization
Software-defined networking (SDN) separates the control plane from the data plane, giving you centralized visibility and programmable control over traffic flows. For AI applications with variable workloads, this flexibility is invaluable.
SDN allows you to dynamically route AI inference requests based on real-time network conditions, automatically steering traffic away from congested paths. You can also implement fine-grained quality of service policies that prioritize time-sensitive AI traffic over less critical data flows, ensuring your edge AI applications get the bandwidth and low latency they need when they need it.
The programmability of SDN means you can adapt routing strategies as your AI deployment scales or as traffic patterns shift throughout the day. This level of control simply isn't possible with traditional static network configurations.
Quality of Service Policies for Traffic Prioritization
Implementing Quality of Service (QoS) allows network traffic to be prioritized, ensuring important applications receive higher priority during congestion. For edge AI deployments, QoS policies ensure that inference requests, model updates, and critical telemetry data get preferential treatment over background traffic.
You can configure QoS at multiple network layers—marking packets with priority tags, allocating dedicated bandwidth to AI traffic classes, or setting up traffic shaping rules that prevent low-priority flows from crowding out latency-sensitive AI workloads. The goal is guaranteeing consistent performance even when your network experiences load spikes.
Effective QoS implementation requires understanding your AI application's traffic patterns and requirements. Real-time inference typically demands both low latency and consistent bandwidth, while batch processing jobs might tolerate higher latency but need sustained throughput. Tailoring QoS policies to these distinct needs maximizes overall network efficiency.
Sources
Continuous Monitoring and Proactive Troubleshooting Methods
Optimizing network speed for AI applications isn't a one-time project—it's an ongoing commitment. Even the best-designed fiber network can experience performance degradation over time due to equipment wear, configuration drift, or changing traffic patterns. That's why continuous monitoring and proactive troubleshooting are essential for maintaining the low-latency performance your edge AI applications demand.
Establishing Performance Baselines for Network Speed
Before you can identify problems, you need to know what "normal" looks like. Measuring and monitoring network traffic establishes a baseline of normal performance, which helps in identifying when and how to optimize the network. Track key metrics during typical operating conditions—bandwidth utilization, latency, jitter, and packet loss—across different times of day and workload scenarios.
Once you've established these baselines, any deviation becomes immediately visible. A sudden spike in latency or an increase in packet loss can indicate emerging issues before they impact your AI applications. This proactive approach allows you to address problems during maintenance windows rather than during critical operations.
Key Metrics to Monitor Continuously
Regular monitoring of key performance metrics like bandwidth utilization, latency, and packet loss is crucial for sustained network performance. For AI workloads, pay particular attention to end-to-end latency measurements between edge devices and processing nodes. Don't just monitor averages—track percentile distributions to catch intermittent issues that might affect real-time decision-making.
Beyond the basics, monitor application-specific metrics. Track inference completion times, queue depths at processing nodes, and data pipeline throughput. These application-layer measurements often reveal bottlenecks that network-layer metrics alone might miss.
Identifying and Diagnosing Common Latency Bottlenecks
When latency issues arise, systematic troubleshooting helps pinpoint the root cause. Start by segmenting your network into logical zones—access layer, aggregation layer, core network, and edge data centers. Measure latency at each boundary to isolate where delays are occurring.
Common culprits include oversubscribed links, misconfigured quality-of-service policies, inefficient routing paths, and aging hardware. Use packet capture tools to examine traffic patterns and identify whether latency spikes correlate with specific application behaviors or time-of-day patterns. Sometimes the issue isn't network infrastructure at all—it might be processing delays at endpoints or storage bottlenecks.
Proactive Maintenance Strategies
Prevention beats reaction every time. Schedule regular firmware updates for network equipment, but test them in non-production environments first. Implement automated health checks that verify configuration consistency across devices and alert you to drift from approved standards.
Consider implementing predictive maintenance based on equipment telemetry. Many modern network devices report temperature, power consumption, and error rates that can indicate impending failures. Replacing a switch before it fails is far better than troubleshooting an outage at 2 AM.
Building an Effective Monitoring Stack
Your monitoring infrastructure should provide visibility at multiple layers. Network flow analysis reveals traffic patterns and helps identify congestion points. Active probing with synthetic transactions validates end-to-end performance from the perspective of your AI applications. Log aggregation and correlation help connect network events with application behavior.
Set intelligent alerts that distinguish between noise and genuine issues. Alert fatigue is real—if your team ignores notifications because most are false positives, they'll miss the critical ones. Tune thresholds based on your baseline data and use anomaly detection to catch unusual patterns that static thresholds might miss.
Sources
Practical Implementation: Building a Low-Latency Network for Edge AI
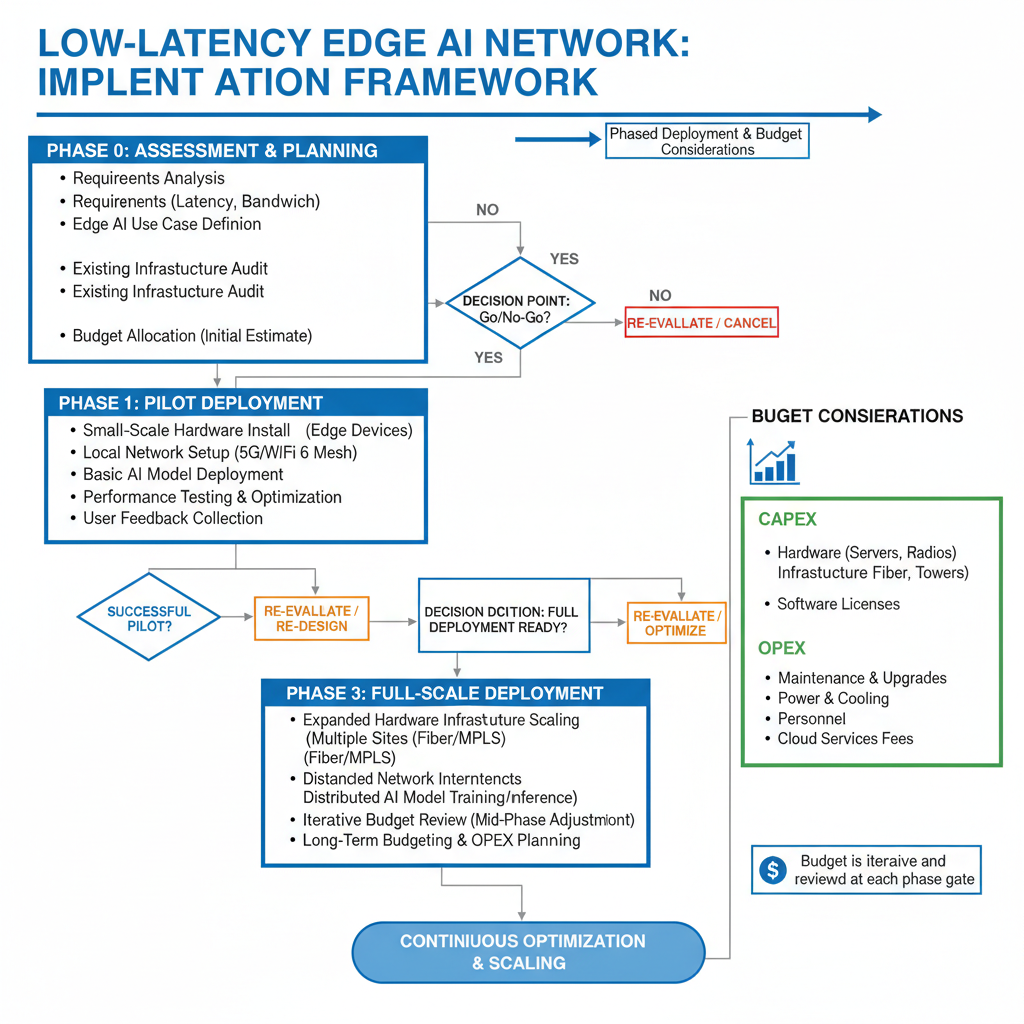
Building a low-latency network for edge AI doesn't happen overnight. It requires a thoughtful, phased approach that balances technical requirements with budget realities. The key is to start with a clear assessment of your current infrastructure and AI workload demands, then prioritize improvements that deliver the most immediate impact on network speed.
Phase 1: Assessment and Planning
Begin by conducting a comprehensive audit of your existing network infrastructure. Map out current latency bottlenecks, identify critical data paths for AI workloads, and establish baseline performance metrics. This initial phase should also include stakeholder alignment on performance targets and budget allocation.
Document your AI application requirements in detail. Understanding whether you're supporting real-time inference, batch processing, or a hybrid model will directly influence your infrastructure decisions. Different AI workloads have vastly different latency tolerances, and your network design should reflect these nuances.
Phase 2: Quick Wins and Foundation Building
Start with optimizations that require minimal capital investment but deliver measurable results. Software-level improvements like protocol tuning, routing optimization, and traffic prioritization can often reduce latency by 15-30% without hardware upgrades.
Simultaneously, begin laying the groundwork for longer-term improvements. This might include negotiating with edge data center providers, evaluating equipment vendors, or piloting new monitoring tools. These foundational steps set the stage for more substantial infrastructure changes.
Phase 3: Infrastructure Deployment
With quick wins in place and planning complete, move to strategic infrastructure investments. Deploy edge data centers closer to data sources, upgrade network hardware at identified bottleneck points, and implement advanced routing capabilities.
Take a modular approach to deployment. Rather than attempting a complete overhaul, focus on one critical path or application at a time. This allows you to validate improvements, learn from implementation challenges, and adjust your strategy before scaling across the entire network.
Budget Considerations and ROI Framework
Develop a tiered budget that separates must-have investments from nice-to-have enhancements. Core infrastructure like edge data centers and high-performance switches typically represent 60-70% of the budget, while monitoring tools, software optimizations, and ongoing maintenance account for the remainder.
Calculate ROI based on both hard and soft benefits. Hard benefits include reduced cloud egress costs, lower bandwidth consumption, and decreased equipment failure rates. Soft benefits encompass improved AI model performance, faster time-to-insight, and enhanced user experience—metrics that may not show up immediately on the balance sheet but drive long-term competitive advantage.
Implementation Roadmap
A practical 12-18 month roadmap typically follows this pattern:
Months 1-3: Complete infrastructure assessment, establish performance baselines, implement software-level optimizations, and secure budget approval.
Months 4-8: Deploy initial edge infrastructure, upgrade critical network hardware, implement monitoring and alerting systems, and begin pilot testing with select AI workloads.
Months 9-12: Scale successful pilots across additional applications, refine routing and traffic management policies, and establish ongoing maintenance protocols.
Months 13-18: Optimize based on real-world performance data, address any remaining bottlenecks, and plan for next-generation requirements.
Organizational Alignment and Skills Development
Technical implementation is only part of the equation. Ensure your team has the skills and knowledge to manage a low-latency AI infrastructure. This may require training existing staff on new monitoring tools, hiring specialists with edge computing expertise, or partnering with managed service providers.
Establish clear ownership and accountability for network performance. Create cross-functional teams that include network engineers, AI/ML specialists, and application developers. This collaborative approach ensures that latency optimization isn't treated as purely a network problem but as a shared responsibility across the technology stack.
Continuous Improvement Mindset
Treat your low-latency network as a living system that requires ongoing attention and refinement. As AI workloads evolve and data volumes grow, your infrastructure needs will shift. Build flexibility into your architecture from the start, choosing solutions that can scale and adapt rather than requiring complete replacement.
Regularly revisit your performance metrics and KPIs. What constitutes acceptable latency today may be inadequate six months from now as AI models become more sophisticated and user expectations rise. Stay ahead of these trends by monitoring industry developments and maintaining relationships with technology vendors who can provide early access to emerging solutions.
Sources
Conclusion
Reducing AI latency isn't just a technical challenge—it's a business imperative. As edge AI applications become more sophisticated and widespread, the networks supporting them must evolve to meet increasingly demanding performance requirements. The nine strategies we've explored provide a comprehensive framework for optimizing network speed and minimizing latency across your infrastructure.
From deploying edge data centers closer to data sources to implementing smart routing protocols, each strategy plays a vital role in creating a low-latency environment. Hardware upgrades, protocol selection, and continuous monitoring work together to ensure your network can handle real-time AI workloads efficiently. The key is understanding that these strategies aren't isolated solutions—they're interconnected components of a holistic approach to network optimization.
Looking back on my experience with fiber network projects, the importance of managing latency in fiber networks became strikingly evident when working with AI-driven applications. Real-time data processing demands leave no room for delays, and thoughtful infrastructure design can significantly boost AI efficiency in ways that directly impact business outcomes.
Taking Action on Network Speed Optimization
The path forward starts with assessment. Evaluate your current network performance using the metrics we've discussed—round-trip time, jitter, packet loss, and throughput. Identify your biggest bottlenecks and prioritize improvements based on your specific AI workload requirements and budget constraints.
Consider a phased implementation approach. Start with quick wins like protocol optimization and monitoring improvements, then move toward more substantial investments in edge infrastructure and hardware upgrades. This staged methodology allows you to demonstrate ROI at each step while building momentum for larger initiatives.
As edge AI continues to evolve, network performance will remain a critical differentiator. Organizations that invest in low-latency infrastructure today position themselves to leverage tomorrow's AI innovations. The strategies outlined in this guide provide a solid foundation, but remember that network optimization is an ongoing process requiring continuous attention and refinement.
The relationship between latency management and AI performance will only grow stronger as applications become more sophisticated. By mastering these nine essential strategies, you're not just improving network speed—you're enabling the next generation of AI-powered solutions that can transform your operations.